线程池之ThreadPool与ForkJoinPool
一、 ThreadPool Executor
一个线程池包括以下四个基本组成部分:
1、线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
2、工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
3、任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
4、任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
工作方式:
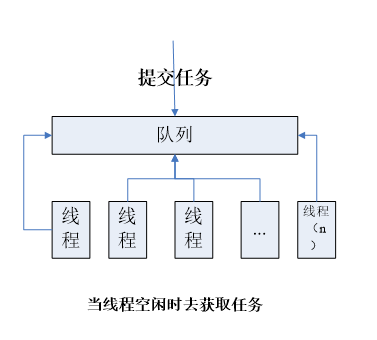
线程池有一个工作队列,队列中包含了要分配给各线程的工作。当线程空闲时,就会从队列中认领工作。由于线程资源的创建与销毁开销很大,所以ThreadPool允许线程的重用,减少创建与销毁的次数,提高效率。
流程图细节:
1.2 ForkJoinPool Executor
ForkJoinPool组成类:
1,ForkJoinPool:充当fork/join框架里面的管理者,最原始的任务都要交给它才能处理。它负责控制整个fork/join有多少个workerThread,workerThread的创建,激活都是由它来掌控。它还负责workQueue队列的创建和分配,每当创建一个workerThread,它负责分配相应的workQueue。然后它把接到的活都交给workerThread去处理,它可以说是整个frok/join的容器。
2,ForkJoinWorkerThread:fork/join里面真正干活的"工人",本质是一个线程。里面有一个ForkJoinPool.WorkQueue的队列存放着它要干的活,接活之前它要向ForkJoinPool注册(registerWorker),拿到相应的workQueue。然后就从workQueue里面拿任务出来处理。它是依附于ForkJoinPool而存活,如果ForkJoinPool的销毁了,它也会跟着结束。
3,ForkJoinPool.WorkQueue: 双端队列就是它,它负责存储接收的任务。
4,ForkJoinTask:代表fork/join里面任务类型,我们一般用它的两个子类RecursiveTask、RecursiveAction。这两个区别在于RecursiveTask任务是有返回值,RecursiveAction没有返回值。任务的处理逻辑包括任务的切分都集中在compute()方法里面。
工作方式:
ForkJoinPool是JDK7引入的线程池。使用一种分治算法,递归地将任务分割成更小的子任务,其中阈值可配置,然后把子任务分配给不同的线程执行并发执行,最后再把结果join组合起来。该用法常见于数组与集合的运算。
也是AbstractExecutorService的子类,引入了“工作窃取”(work-stealing)机制,在多CPU计算机上处理性能更佳。
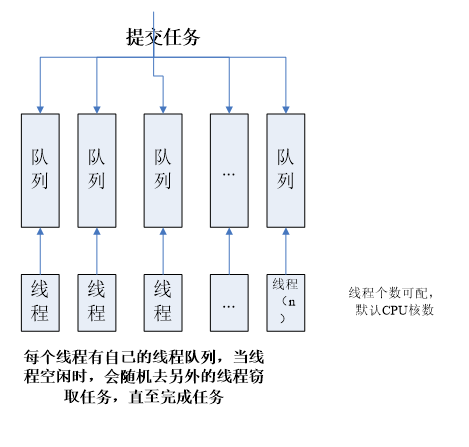
工作窃取机制是ForkJoinPool提供的一个更有效的利用线程的机制,当ThreadPoolExecutor还在用单个队列存放任务时,ForkJoinPool已经分配了与线程数相等的队列,当有任务加入线程池时,会被平均分配到对应的队列上,各线程进行正常工作,当有线程提前完成时,会从队列的末端“窃取”其他线程未执行完的任务,当任务量特别大时,CPU多的计算机会表现出更好的性能。
流程图细节:
1.3 应用场景
1、应用场景对比
ThreadPool
- 常用于线程并发,阻塞时延较长的任务。这种任务一般要求的线程个数较多;(IO密集型)
ForkJoinPool
- 用于大任务可分解成小任务,一般是非阻塞的、可以快速处理的任务;或者阻塞时延较小的任务。CPU密集型(CompletableFuture默认就是、以及java stream的parallelStream也是)
2、基本功能原理
ThreadPool
- 其思想就是实现造出一批线程放到一个集合中,等到有任务来的时候,直接从线程集合中取出一个线程执行任务。这样就把每个线程的创建、连接、销毁等过程统一管理,节省系统时间,提高系统稳定性。
ForkJoinPool
- 类似于MapReduce任务分解聚合模式, ForkJoinPool采用先将大任务fork成多个小任务,然后再将每个小人物的接口join在一起,进而得出大任务的结果。
3、阻塞队列个数
ThreadPool
一般是一个阻塞队列。阻塞队列的类型有:
- ArrayBlockingQueue :是一个有界缓存队列,可以指定缓存队列的大小。当正在执行的线程数等于核心线程数时,新的任务会放到ArrayBlockingQueue队列中,当ArrayBlockingQueue队列已满时,会新开线程执行任务,等到线程数等于最大线程数时,再进来的任务时ArrayBlockingQueue就会报错;
- LinkedBlockingDeque :是一个无界缓存等待队列,当前执行的线程数等于核心线程数时,新来的任务就会在LinkedBlockingDeque队列中等待(从现像上看使用该缓存队列时最大线程数参数相当于无效了);
- SynchronousQueue :SynchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
ForkJoinPool
- 每个线程都有一个队列。如果一个线程的队列执行完成,可以从其他线程队列的末尾拿出一个任务执行;
参考:https://blog.csdn.net/larva_s/article/details/90403578
ForkJoinPool.commonPool() (并行流、CompletableFuture默认就是这个)。默认线程数是:cpu核心数-1
Runtime.getRuntime().availableProcessors() - 1
如何自定义:
System.setProperty(“java.util.concurrent.ForkJoinPool.common.parallelism”, “8”);
或者:启动参数指定
-Djava.util.concurrent.ForkJoinPool.common.parallelism=8线程数设定原则:
IO密集型:CPU核心数*2
CPU密集型:趋近于CPU核心数
网络请求、jdbc这些都属于IO密集型
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。